Against SES as a Construct
Socioeconomic status, or SES, is a measure used by sociologists and economists that serves as a rough proxy of social class. It typically combines several measures, such as income, education, and occupational status. It’s also a bad measure because combining several measures into a single SES score usually smuggles in a causal model that researchers do not state, justify, or believe, which hides what income, education, and occupation are actually doing. Researchers should usually stop using SES as a single variable and instead model income, education, and occupation directly.
SES is not a reflective construct
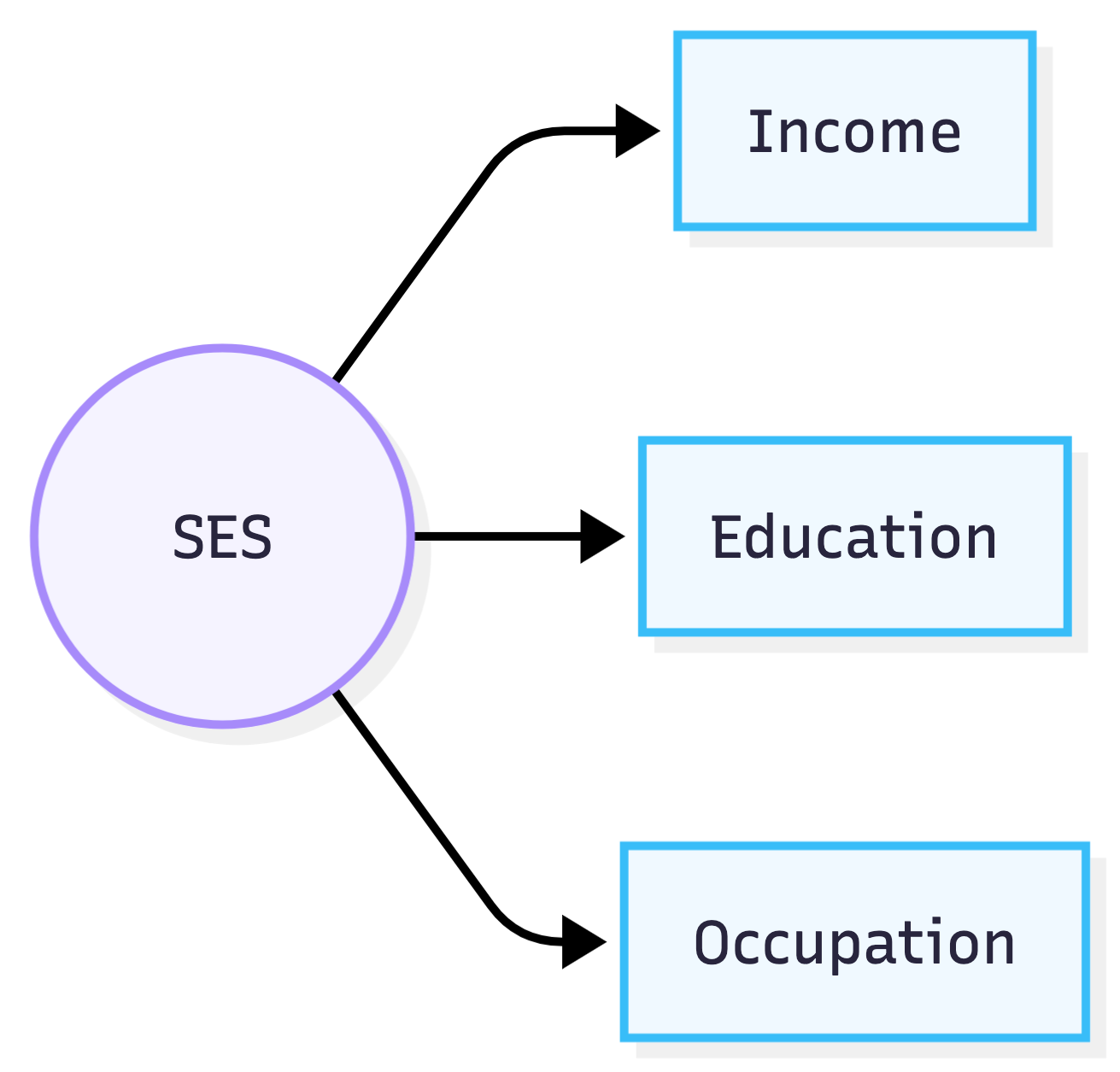
SES is often treated as a latent construct, which we usually model using structural equation modeling or factor analysis. There are two relevant types of factor models, distinguished by the assumed direction of causation between the construct and its indicators: reflective and formative. A reflective model is the typical approach: the latent variable is assumed to be the common cause of the indicators; it’s why the indicators correlate. An example is sociability, which we model as causing one to like small talk, have a lot of friends, and like talking in front of crowds. Under this model, SES would be one of the reasons income, occupation, and education are correlated. This is causally implausible. It seems more plausible that, for example, occupation is correlated with income because occupation is a major determinant of income, and that education is correlated with occupation because education is a major determinant of occupation.
Formative SES has a weight problem
So we turn to the formative model. In a formative factor model, the indicators cause the latent construct, rather than being caused by the construct. In our case, this means income, occupation, and education are treated as variables that help determine SES. But this immediately raises the question of weights: how much should each component contribute?
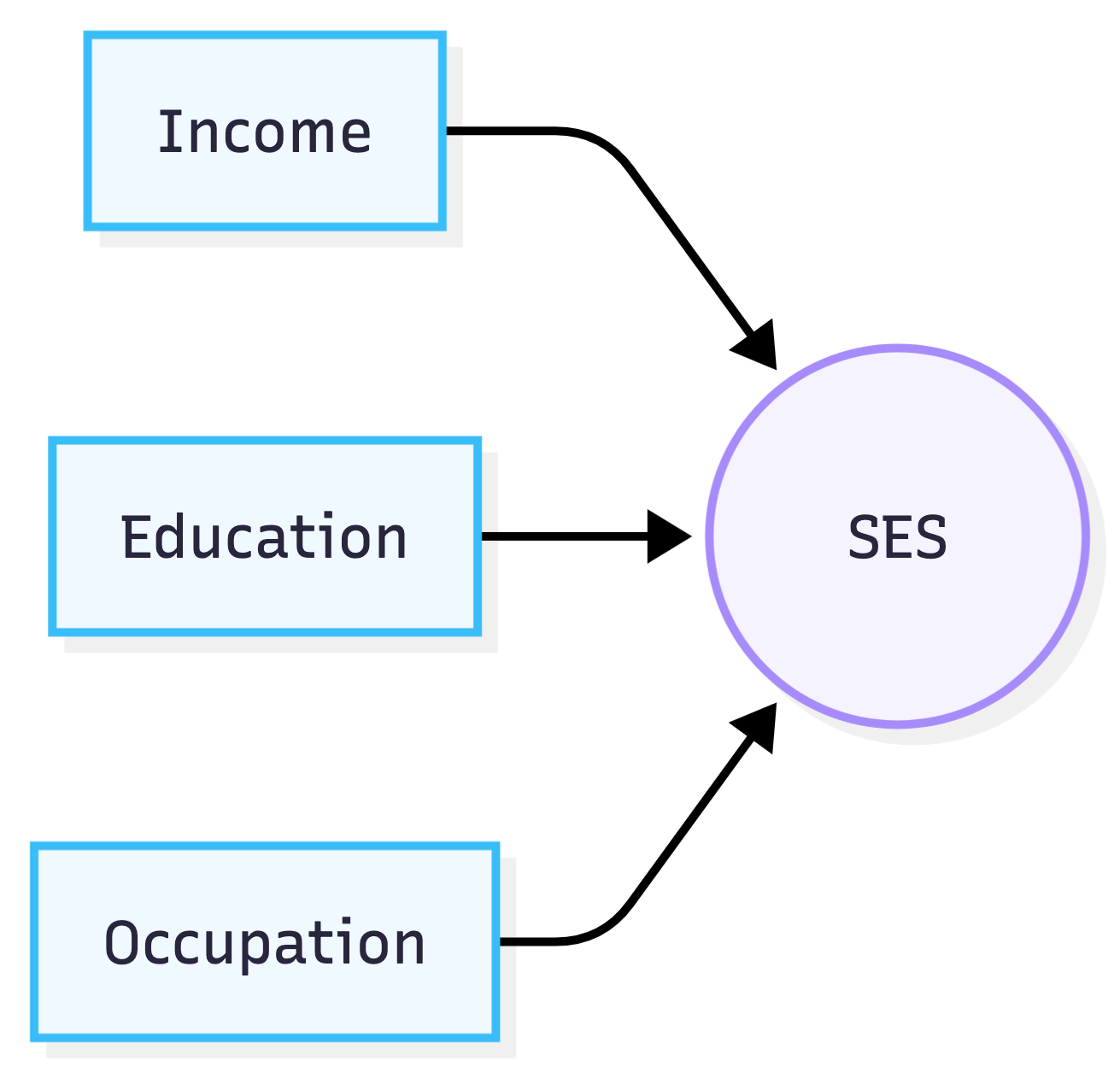
Now, for a reflective model, we determine the factor loadings—roughly, how strongly an indicator relates to the factor—by finding the loadings that imply the observed correlations. We can’t do this for formative models because the correlations among the indicators do not tell us how much each indicator should contribute to the construct. In the simple reflective factor model, the indicators are assumed to be independent conditional on the latent construct(s)1; the formative model doesn’t make this assumption. So while reflective models can use the covariance structure of the indicators to estimate the latent variable, formative models need some other way to determine how the indicators relate to the construct.
There are three common ways to determine the weights in formative factor models. We can assign them arbitrarily, we can determine them by seeing which weights best predict an external criterion, or we can use a Multiple-Indicator Multiple-Causes model, or MIMIC model.
Equal weights need justification
The problem with the first method is that there’s no principled basis for choosing one set of weights over another. So, you might decide to weight all components equally.
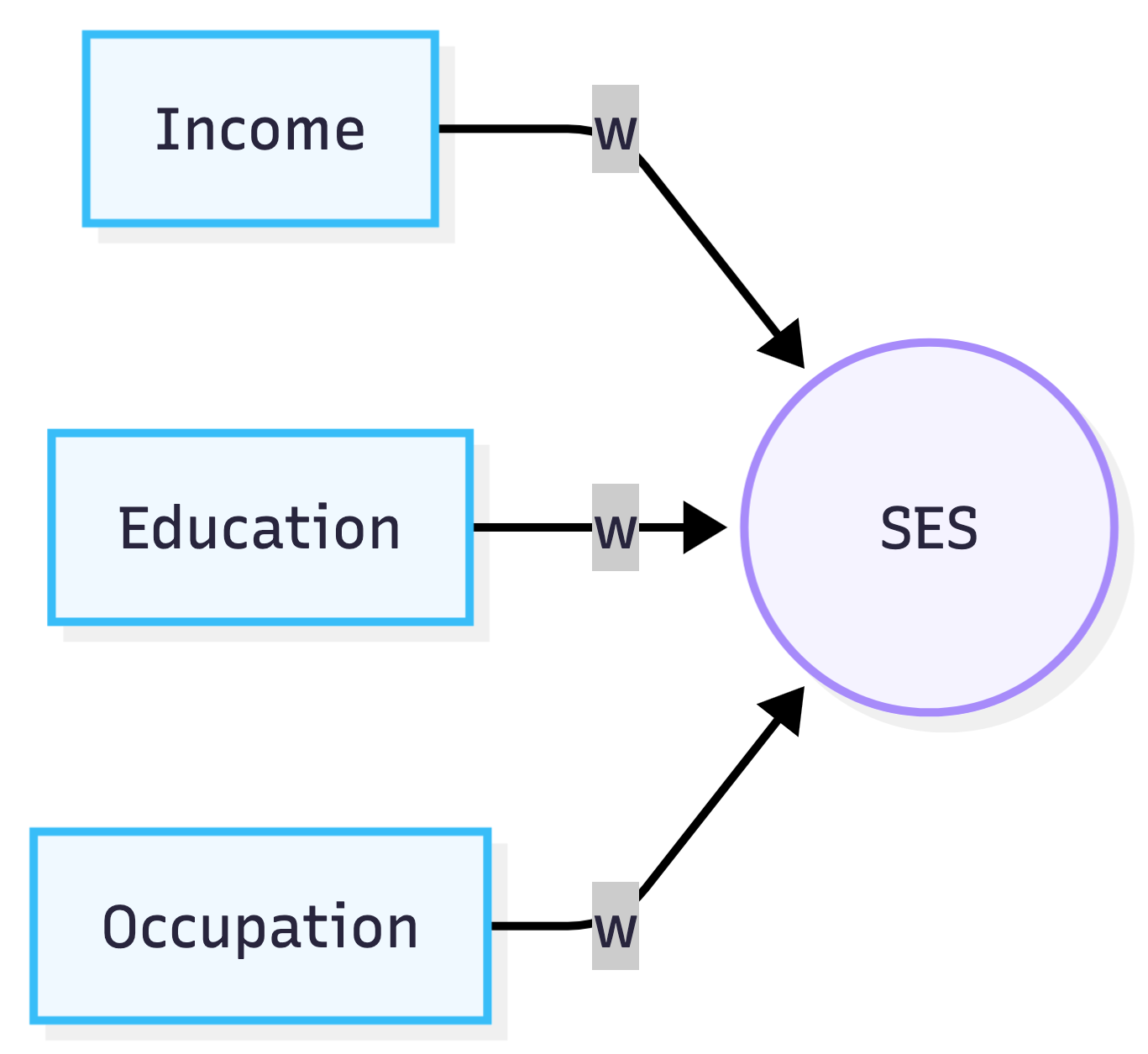
Equal-weighting can, in some cases, be a pragmatic choice: if the indicators are highly correlated and the goal is just rough estimation, it may work about as well as more complex methods. But this should not be treated as a serious model of socioeconomic status. Equal-weighting makes an assumption that all components contribute equally to SES, which should be explicitly stated and tested.
Regression-derived SES is just regression
The problem with the second method is that, by choosing the weights to predict a single external criterion, we’re essentially just doing linear regression. This can be useful if our goal is prediction, but then the resulting score is specific to that criterion.
A set of weights chosen to predict financial security is not automatically a general measure of socioeconomic status, and if we’re going to use it that way, it’s best to stop the facade and just call it a regression-derived predictor.
MIMIC models make the assumptions explicit
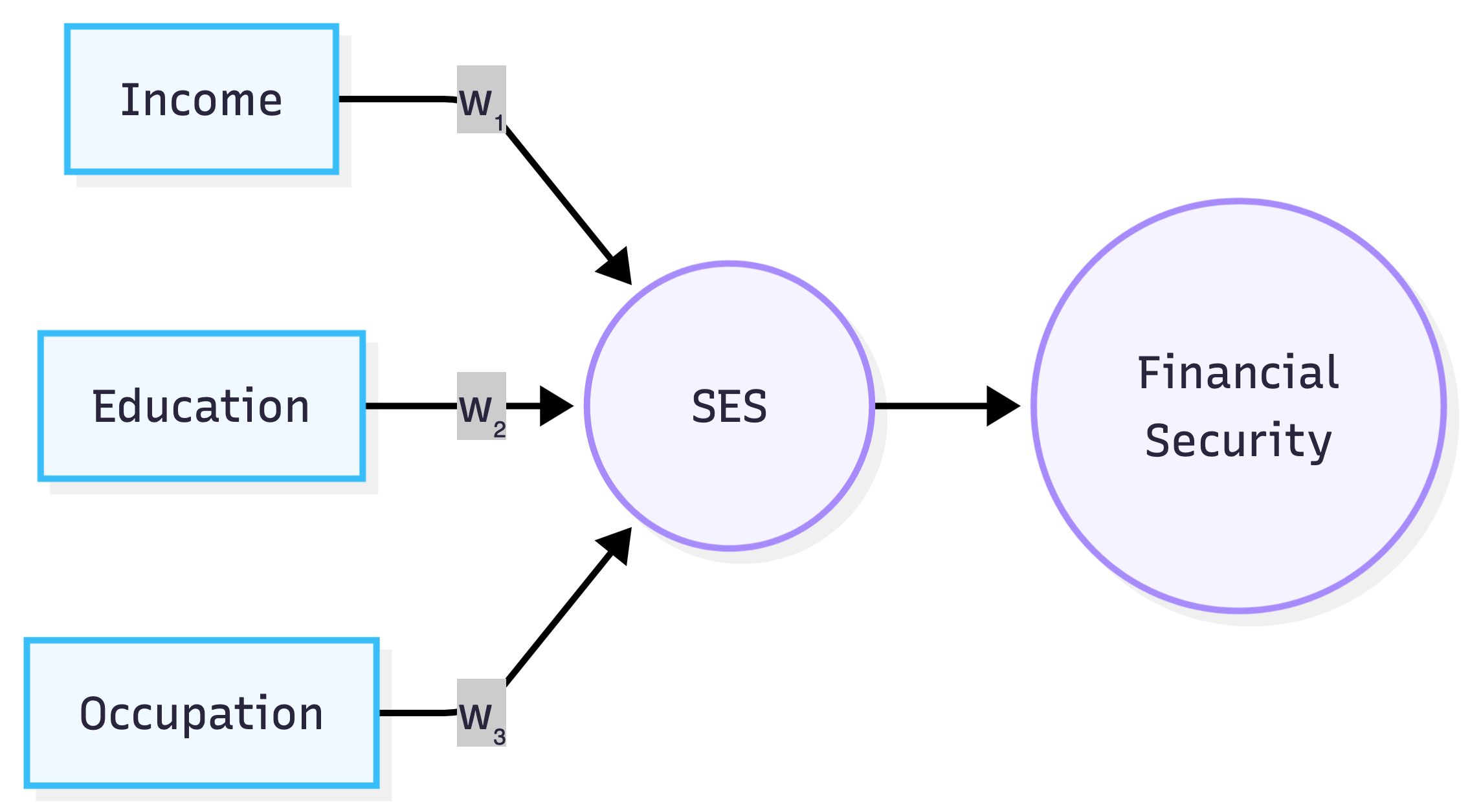
Using a MIMIC model is a much more explicit alternative. It makes explicit one of the assumptions we rely on when we say things like “high SES causes financial security”. For example, if we draw it out, we see that we’re implicitly assuming SES mediates the relationship between causes like income, education, occupation, and effects like financial security, which the MIMIC model actually models.
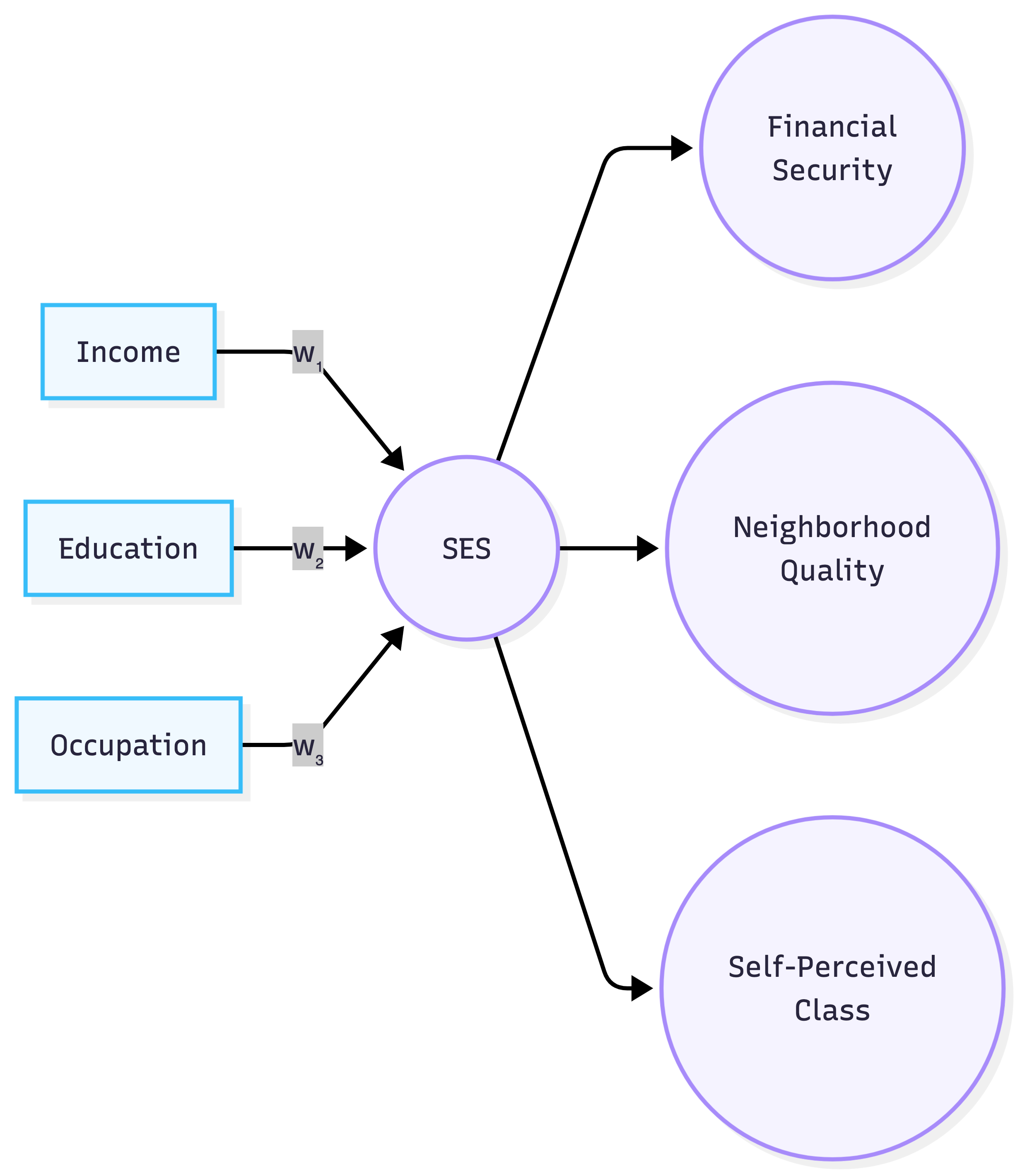
Instead of leaving these assumptions implicit, we should state them explicitly, decide whether we believe them, and then check whether the model fits. If SES is useful as a concept, we should see that the same set of weights is predictive of many outcomes. More precisely, a model using SES would pay rent if income, education, and occupation combined into a stable latent score that explained a broad set of relevant indicators. Adding separate direct paths from income, education, and occupation should not substantially improve fit or change the conclusions. This SES measure should predict not only financial security, but also, for example, neighborhood quality, self-perceived class, and more. If instead income, education, and occupation have different direct effects on different indicators, then the single-SES model should fail, or at least need those direct paths added explicitly.
The causal story still looks wrong
Of course, when we think about the model’s implications, we see that the model makes implausible causal assumptions. For example, the pure mediation model says that income affects financial security only through SES, with no direct path from income to financial security. But this is implausible: income seems to have a direct effect on financial security because having a higher income allows one to save more money. The same is true of neighborhood quality: higher income directly enables people to afford to move into nicer neighborhoods. It seems unlikely that the pure mediation model is one that researchers endorse, which raises the question of why they keep using it.
Unfortunately, most SES research doesn’t even get this far. MIMIC models seem uncommon in SES research, at least compared to simple composites, single proxies, and standardized/equal-weighted indices, which often lack a model explaining why those components should be combined in that specific way.
Even the components are messy
Even if we set aside the weighting problem, SES has another problem: in most research analyses, it needs to be a number. So, we need to convert its components into numbers. In the case of income and education, this is relatively simple, though not trivial.2 Income is already numeric, though we might transform it by taking the logarithm, using percentile ranks, or binning it. Education is also numeric if you consider years of schooling, though it is usually binned as well. Occupation is trickier. There are two main ways to convert it to a number. First, you could ask people how prestigious various occupations are. Second, you could create a score from the average education and income of people in that occupation. The former method is conceptually cleaner, at least if you’re interested in perceived occupational status. I don’t like the latter method, though: if you also include individual income and education, it risks double-counting them, or at least mixing individual-level income and education with occupation-level income and education in a way that makes the model difficult to interpret. This could theoretically be useful, but it should be modeled explicitly rather than smuggled into a single SES score.
Model the components directly
So, what do I propose instead? Instead of trying to combine variables into a lossy, unprincipled socioeconomic status construct, model the components directly, according to the causal role each is supposed to play with respect to the outcome at hand. We don’t expect the ratio of the impact of the variables to be the same for every outcome. For some things, education has an outsized effect; for others, income does. If you’re going to use socioeconomic status, then your model’s assumptions should be stated and its implications tested.
-
More flexible structural equation models can relax this assumption by including correlated residuals, additional latent variables, cross-loadings, or method factors. The point isn’t that reflective SEMs require every indicator correlation to be explained by a single latent construct, but that the basic reflective identification strategy gets information from the covariance structure among the indicators, while a purely formative model cannot determine its weights from the covariance structure. ↩
-
For income, you still have to decide whether to use individual income, household income, equivalized household income, pre-tax income, post-tax income, current income, permanent income, wealth, assets, debt, local cost-of-living-adjusted income, and so on. For education, years of schooling is numerically convenient, but credentials are not really interval-scaled: the difference between 11 and 12 years of schooling is not necessarily comparable to the difference between 15 and 16 years, and educational meaning also varies by e.g., country and period. ↩