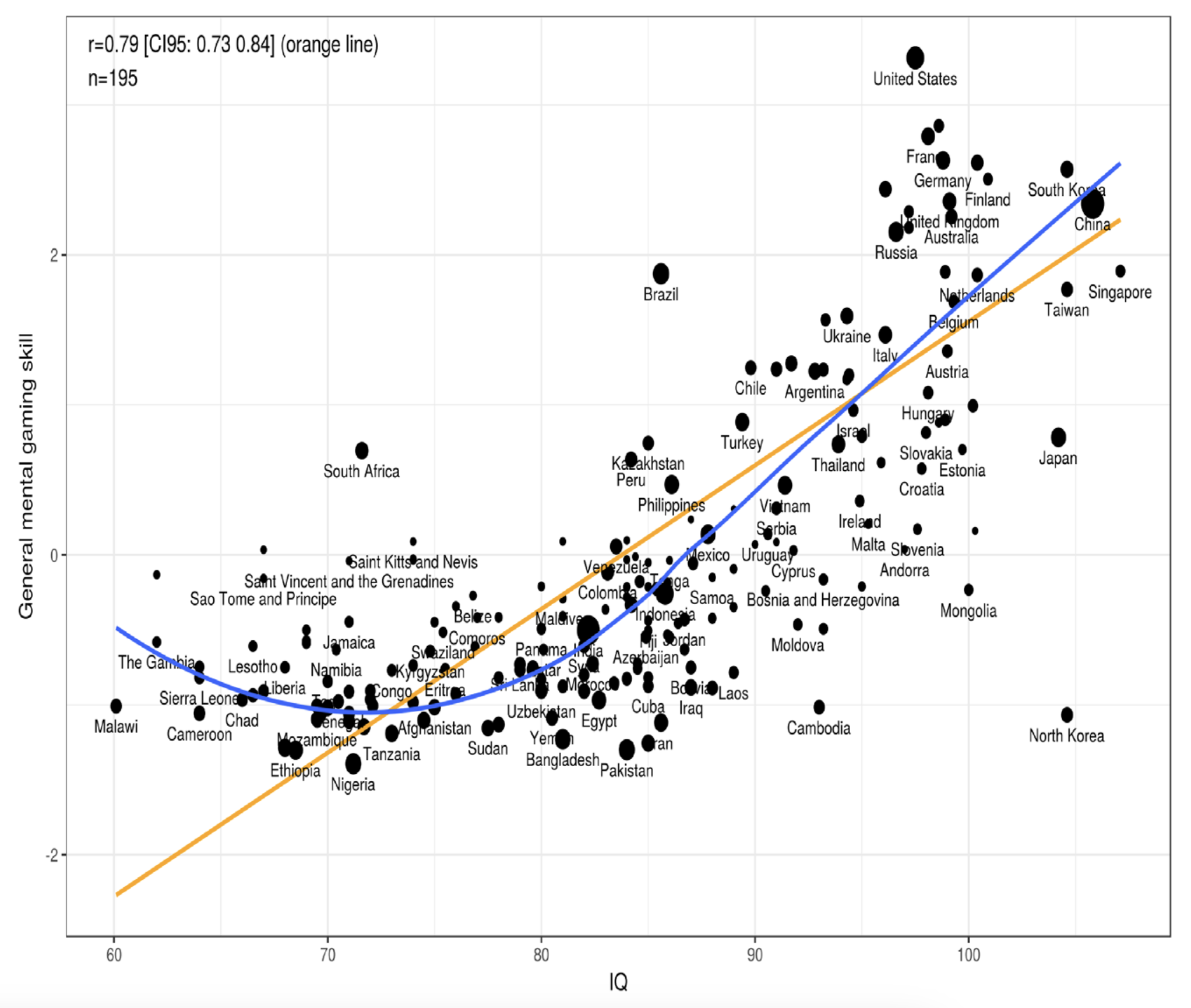
The earring is a little topaz tetrahedron dangling from a thin gold wire. When worn, it whispers in the wearer’s ear: “Better for you if you take me off.” If the wearer ignores the advice, it never again repeats that particular suggestion.
— Scott Alexander, Clarity didn’t work, trying mysterianism
In his short story, Clarity didn’t work, trying mysterianism, Scott Alexander describes an earring that whispers advice into the ear of its wearer. At first, it offers guidance only on major life decisions. Over time, however, the advice becomes increasingly fine-grained, eventually extending to moment-by-moment instructions about which muscles to contract, and by how much. The earring is always right. It does not always give the objectively best advice, but its guidance is always better, in terms of the wearer’s happiness, than what the wearer would have come up with on their own. Scott argues that the earring is dangerous because, although it delivers a perfect life, it gradually erodes free will. But free will is overrated.
Humans Should Not Make Choices
Man is not a rational animal; he is a rationalizing animal.
— Robert A. Heinlein
In his landmark Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence, Paul Meehl shows that clinicians in psychiatry are worse at diagnosing patients and predicting outcomes than simple statistical models. This holds despite the claim that psychiatry is too nuanced and complex for such models, requiring holistic judgment that cannot be captured by simple numerical predictors. According to a review published five decades later, simple statistical models outperform experts in predicting outcomes as diverse as academic performance, delinquency, career satisfaction, length of hospital stays, and more.
At first glance, this might seem unsurprising. We should not expect humans to be able to precisely calculate the optimal weight to assign to each predictor. In The Robust Beauty of Improper Linear Models in Decision Making, however, Robyn Dawes undermines even this defense. Experts are not merely outperformed by proper linear models; they are outperformed by improper ones—models whose weights are chosen using explicitly suboptimal procedures. One such example is the equal-weighting model, in which predictors’ signs are chosen a priori but all weights are set to unit magnitude.
Prediction is not the only domain in which humans systematically go awry. It’s likely that people miscalibrate explore-exploit tradeoffs: in some domains, such as choosing movies or books, they explore too much, while in others, such as music preferences or romantic partners, they exploit too early and too much. There are many other well-documented ways in which people fail to act optimally. People fall prey to the sunk cost fallacy, persisting in failing courses of action simply because they have already invested time or resources in them. They exhibit hyperbolic discounting, sacrificing larger future rewards for smaller immediate ones even when doing so conflicts with their stated long-term goals. They under-experiment, failing to gather information that would materially improve future decisions. As Gwern has noted, we can’t even trust humans to rate things out of 5 stars. These failures have many proximate causes: limited and fallible memory, heuristics adapted to past environments, constrained processing capacity, and the fact that we simply think too slowly. In addition, humans often lack the courage or willpower to follow through on what they themselves judge to be best. None of these excuses change a fundamental truth: Humans are systematically unreliable; therefore humans should not make decisions.
Motivations, Magic, and Math
I like to decompose decision-making into three components: motivations, magic, and math. In brief, we must (1) determine our preferences, (2) mathematize all relevant aspects of the problem and environment, and (3) solve the resulting optimization problem.
Motivations
It is better to be a human being dissatisfied than a pig satisfied; better to be Socrates dissatisfied than a fool satisfied. And if the fool, or the pig, is of a different opinion, it is only because they only know their own side of the question.
— John Stuart Mill
Eliciting preferences seems not particularly hard, though it does require caution. Preferences are often broken down into two components: wanting and liking. Wanting describes motivation. In this sense, the goals we want are those we crave, feel drawn toward, or are motivated to act on in the moment. For example, you might strongly ‘want’ to scroll social media late at night. Liking describes pleasure. These are the activities we enjoy while doing them and that feel subjectively pleasant or rewarding. For example, you might like eating dessert or watching a familiar sitcom. An activity can satisfy both of these (e.g., romantic love), or neither (e.g., hitting yourself in the face with a hammer). Unfortunately, neither of these is sufficient for our purposes.
To understand why I say wanting is insufficient, know this: humans are so very ignorant. What we want most is often not what will most satisfy us. The problem is not only what we do want, but also what we fail to want. We do not crave filing paperwork, asking someone out, or practicing an instrument, even though we very much crave the results of those actions. In a better world, our short-term urges would exert less influence over our behavior. What we need instead is something more reflective and far-sighted calling the shots, ensuring that our actions are oriented toward what is truly good for us.
To understand why liking is insufficient, consider this: chasing pleasure leads to wireheading in the limit. I judge this undesirable. I wish to be more than a god sitting on a lotus throne in a state of permanent cosmic bliss until the end of existence; I wish to build, explore, and struggle toward meaningful ends, even though that means I will not experience maximum pleasure at all times.
In Approving reinforces low-effort behaviors, Scott Alexander breaks down preferences into not two, but three components: wanting, liking, and approving. Approving describes ego-syntonicity: the desires that we endorse upon reflection, and judge to be worthwhile. For example, you might approve of exercising regularly or working on a long-term project. If liking corresponds to hedonic utilitarianism, whose end state is a universe of blissed-out Buddhas, then approving corresponds more closely to preference utilitarianism, whose end state is a universe in which those who truly, on reflection, want to ascend into eternal bliss can do so, while those of us who wish to do something else, even at the cost of our happiness, are able to do that as well. One’s goal, then, should be something like their coherent extrapolated volition: what they would want if they knew more, thought faster, were more the person they wish to be, had grown up further, where the extrapolation converges rather than diverges, where their desires cohere rather than interfere, extrapolated as they wish them extrapolated, interpreted as they wish them interpreted.
Magic
All is number.
— Pythagoras
In Decision Theory with the Magic Parts Highlighted, moridinamael notes that even the simplest decision theory problems require “magic”. I will use this term to refer to the process of fully mathematizing our environment: converting all relevant aspects of the problem into mathematical objects.
One relatively simple way to mathematize aspects of the real world is through embeddings. Embeddings allow us to represent objects as points in a high-dimensional space. They are extremely useful, enabling us to quantify similarity, cluster items, transfer information across related items, and support statistical/ML inference.
However, in the same post, moridinamael offers a more concrete breakdown of what this “magic” consists of. Magic involves three distinct operations:
- Selecting and discretizing the relevant choices and outcomes from a vast space of possibilities
- Projecting latent preferences onto those modeled outcomes via utility assignments
- Assigning probabilities to potentially novel situations using predictive models
While embeddings are effective at representing objects such as text, images, and music, they are much less effective at representing outcomes, which is a serious limitation. Once outcomes are represented in a usable form, the other magical operations become more tractable. Utility assignment, for example, can be approached by querying users for utilities over specific outcomes and interpolating from there. Likewise, probabilities can be assigned using standard predictive techniques. But both of these steps presuppose that outcomes have already been represented in the model. That initial representation step is precisely where embeddings alone tend to fail.
Fortunately, for domains where embeddings are insufficient, we now have something far more powerful: machine learning systems with natural language and vision understanding, namely LLM-based chatbots. Modern chatbots can carve up world states in ways that feel intuitive and natural to humans. Once the state space has been structured in this human-aligned way, assigning utilities and probabilities becomes far easier, and LLM-based tools can assist with those steps as well.
Math
The miracle of the appropriateness of the language of mathematics for the formulation of the laws of physics is a wonderful gift which we neither understand nor deserve. We should be grateful for it and hope that it will remain valid in future research and that it will extend, for better or for worse, to our pleasure, even though perhaps also to our bafflement, to wide branches of learning.
— Eugene Wigner, The Unreasonable Effectiveness of Mathematics in the Natural Sciences
Once we have mathematized both our preferences and the environment, what remains is an optimization problem. Thousands of person-years have been spent inventing and refining mathematical optimization algorithms; there is no need for us to invent anything new. All that is required is to select the appropriate tool for the task—and even that can be delegated to the Earring itself.
And why should we hesitate to use mathematics to optimize our own lives? Corporations routinely use math to optimize nearly every aspect of their operation, from supply chains and pricing strategies to advertising placement and employee scheduling. We already accept mathematical optimization when choosing routes on a map, allocating our investments, or scheduling our time to meet deadlines. It should therefore be possible to take the same tools that help organizations function efficiently and apply them at an individual scale.
Visions of an Earring
A thinker sees his own actions as experiments & questions—as attempts to find out something. Success and failure are for him answers above all.
— Friedrich Nietzsche, The Gay Science
The form of the Earring is not set in stone, though for the sake of concreteness, let us imagine it not as an earring but as a pair of glasses. The crucial requirement is that the device must see everything the wearer sees and hear everything the wearer hears. To make the collected data usable, we would also need an AI (or set of AIs) capable of understanding and analyzing video and audio.
One immediate benefit is retrospective question-answering. Currently, if I have a question—such as “When should I check the mail?“—I can only collect data after I have already thought to ask it. If I then think of additional questions, such as “Does exercise affect how long I sleep?” or “How often do I interrupt people in conversation?”, I must separately design and maintain new data-collection processes for each one. The more questions I have, the more burdensome this becomes. With an always-on camera and microphone, this constraint disappears: data collection happens first, and questions come later. If I find myself wondering which of my outfits gets the most compliments, instead of manually tracking reactions, I can simply ask the Earring to search the existing data and answer the question.
Not all questions can be answered using passively collected video and audio alone. For example, my subjective enjoyment of different foods is not directly observable. However, if I can instruct the AI to prompt me—specifically when I am eating—to rate how much I am enjoying a meal, I can collect fine-grained enjoyment data without having to remember to log it myself. This is an instance of experience sampling: periodically querying someone about their thoughts, feelings, or behavior, a technique commonly used in happiness and behavioral research. Our version can be far less intrusive than traditional experience sampling, since the system already knows what I am doing and does not need to ask redundant contextual questions. Of course, this is just a temporary solution until the Earring can read my mind directly.
Once the Earring is collecting data semi-proactively, its capabilities can expand even further. If the human agrees to follow the Earring’s instructions, the Earring can gather information far more efficiently. As Gwern notes in Why Tool AIs Want to Be Agent AIs, adaptive techniques can dramatically outperform fixed-sample techniques in terms of inference quality and cost, for example by allowing experiments to terminate early once sufficient evidence has been gathered. Another example is the use of multi-armed bandit methods to allocate trials or experiences adaptively, concentrating exploration where uncertainty or payoff is highest. The general upshot is that granting the Earring more agency allows it to collect higher-quality information using fewer resources.
Ideally, one would not even need to come up with questions to ask the Earring. A sufficiently capable Earring could generate hypotheses on its own, notice regularities or anomalies in the data, and design analyses or experiments to investigate them. Rather than merely answering questions, the Earring would take on an active role, inferring patterns and steering the wearer’s behavior accordingly.
The Earring can also be extended in obvious ways. In addition to video and audio, it would be valuable to capture external state such as time, location, and weather, as well as internal state via other wearables, including heart rate, sleep metrics, activity levels, biochemical markers, and more. Each additional signal would allow the Earring to answer more questions, refine its model of the wearer, and guide their life more effectively.
So far, I’ve discussed the Earring primarily in an individual context. Things change substantially once multiple people have Earrings. For one, the cold start problem is partially alleviated. If only a single person has an Earring, our priors are barely-informative; if many people have Earrings, we can use far more informative priors. If we are, for example, just getting into movies, instead of watching movies at random, we’re able to start with Parasite. Instead of testing arbitrary sleep interventions (such as standing one-legged), we can focus on those that have worked for many others. This is, after all, why medical trials are useful: a treatment that works across many people is strong Bayesian evidence that it may work for you as well. Shared data also helps with decisions that have long time horizons or sparse feedback, where individual trial-and-error is impractical. The wise person, after all, learns not from his mistakes but from the mistakes of others.
Social interactions benefit as well. With sufficiently rich models of both participants, the Earrings could predict compatibility, help avoid wasted time, and surface opportunities for new friendships or romantic relationships. Much of this would rely not on explicit self-reports but on implicit measures: patterns of attention, affect, conversational flow, shared interests, and unspoken preferences that are often better indicators of the heart’s desires than what people can articulate about themselves. Because this information would be processed primarily by the systems themselves, sensitive or embarrassing details could be used without exposing the users to social risk or self-consciousness. Beyond matchmaking, the Earrings could help maintain existing relationships by avoiding small missteps that quietly erode goodwill, prompting contact at moments when a relationship is beginning to fray, or steering conversations toward topics where both parties are genuinely engaged rather than merely agreeable. In this way, relationships could become less fragile and less dependent on chance timing or social intuition, while still feeling organic to the people involved.
Once we reach this point, a whole class of algorithms become applicable across a wide range of domains: stable matching, auctions, bargaining, fair division, value handshakes, and more. If we are represented by agents that understand our values better than we do, are capable of complex mathematics, and are willing to endure the tedium of exhaustive calculation, these problems become tractable to use everywhere. As a concrete example, consider a group deciding where to eat, attempting to balance enjoyment, novelty, distance, and cost. These factors differ across individuals and are difficult to aggregate, so current solutions are likely highly suboptimal. The Earrings, on the other hand, could resolve this automatically and with far better results than humans could achieve unaided.
Push this logic far enough, and we may finally reach the Economists’ Paradise, where “All game-theoretic problems are solved. All Pareto improvements get made. All Kaldor-Hicks improvements get converted into Pareto improvements by distributing appropriate compensation, and then get made. In all cases where people could gain by cooperating, they cooperate. In all tragedies of the commons, everyone agrees to share the commons according to some reasonable plan. Nobody uses force, everyone keeps their agreements. Multipolar traps turn to gardens, Moloch is defeated for all time.”
Potential Pitfalls
Goodhart’s Law
Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.
— Charles Goodhart
Goodhart’s Law is something we need to be wary of. When a measure becomes a target, it ceases to be a good measure: optimizing too hard for a proxy often pushes us into regimes where the proxy diverges from what we actually care about.
One way to reduce the harms caused by Goodhart’s Law is to limit optimization power. Rather than trying to find the cheapest possible diet that meets a list of nutritional constraints, we might instead aim for a reasonably cheap diet that meets those constraints. The former might yield some pathological, unappetizing mixture of “foods,” potentially missing nutrients we failed to specify, whereas the latter is more likely to resemble a normal, human diet. This is a form of satisficing: deliberately settling for “good enough” rather than pushing optimization to extremes.
Limiting optimization power is nice and all, but it conflicts with the core purpose of the Earring, which is to apply optimization power toward improving our lives. So instead of optimizing less, we might try measuring better.
One approach is to use better proxies. Suppose I am worried about my body fat and want to reduce it. I need a way to measure it, so I might start with BMI, since it is easy to compute and correlates reasonably well with body fat. As with most things, BMI is an imperfect proxy. A decreasing BMI might reflect loss of muscle as well as fat, which is not ideal, and increasing muscle mass would raise BMI even if it made me healthier. A better proxy would be waist-to-height ratio, which is less sensitive to changes in muscle mass, though it can still be affected by factors like posture. I could then use skinfold calipers to estimate body fat more directly; this would be less affected by total muscle mass, but still subject to measurement error and operator variability. Going further, I could use DEXA scans, which are less sensitive to these issues, though they are still subject to noise and assumptions about tissue composition. And so on.
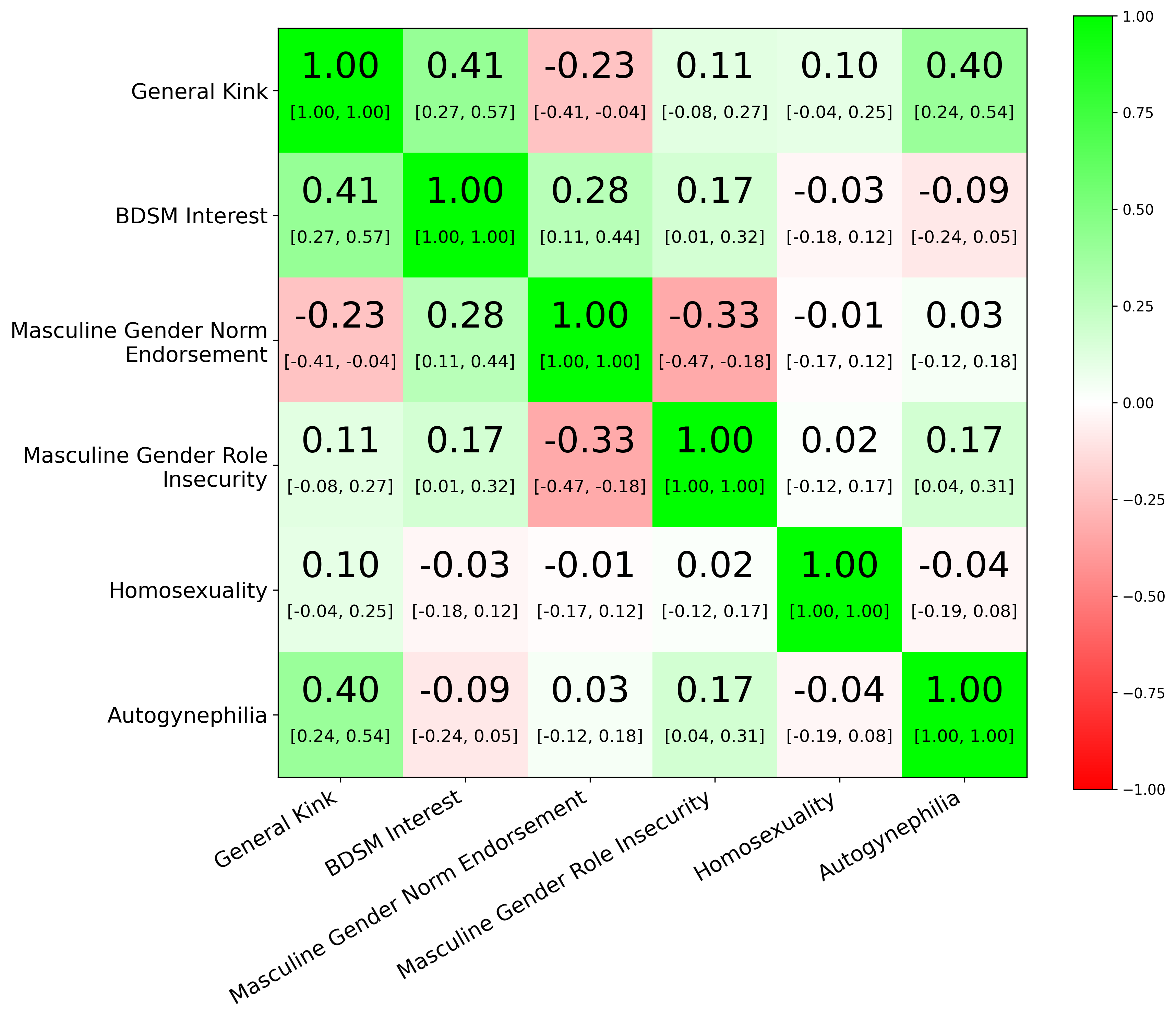
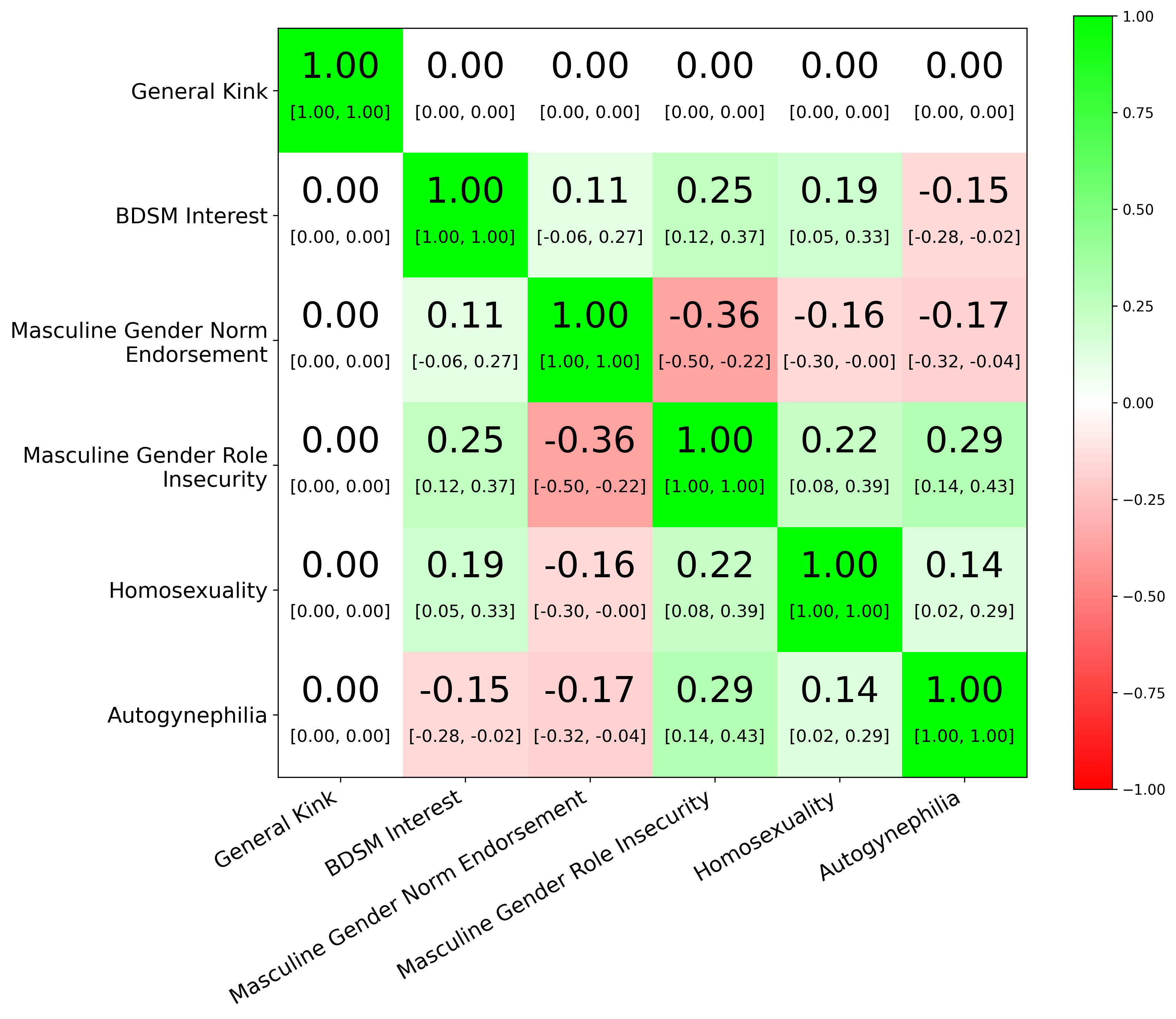
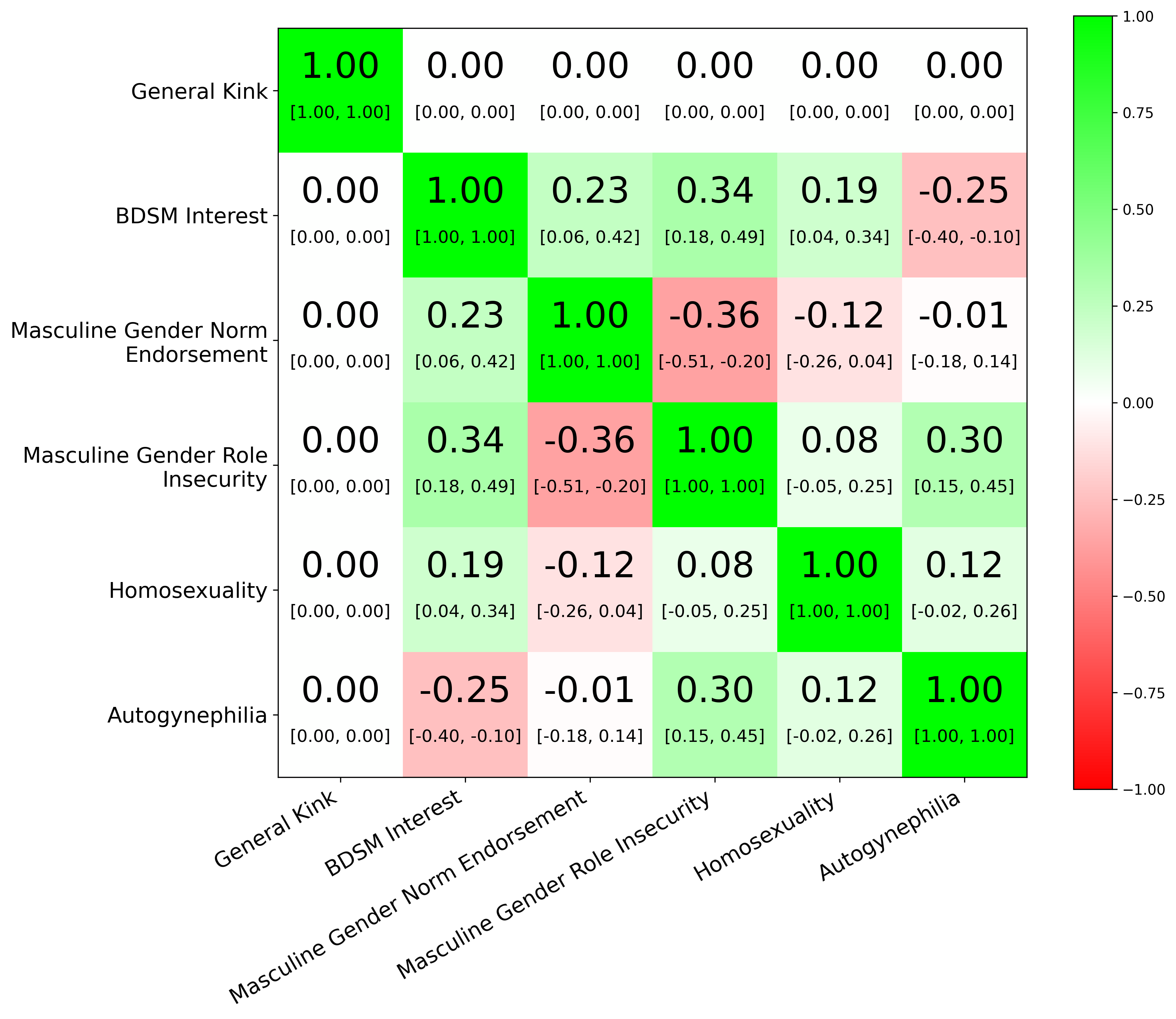
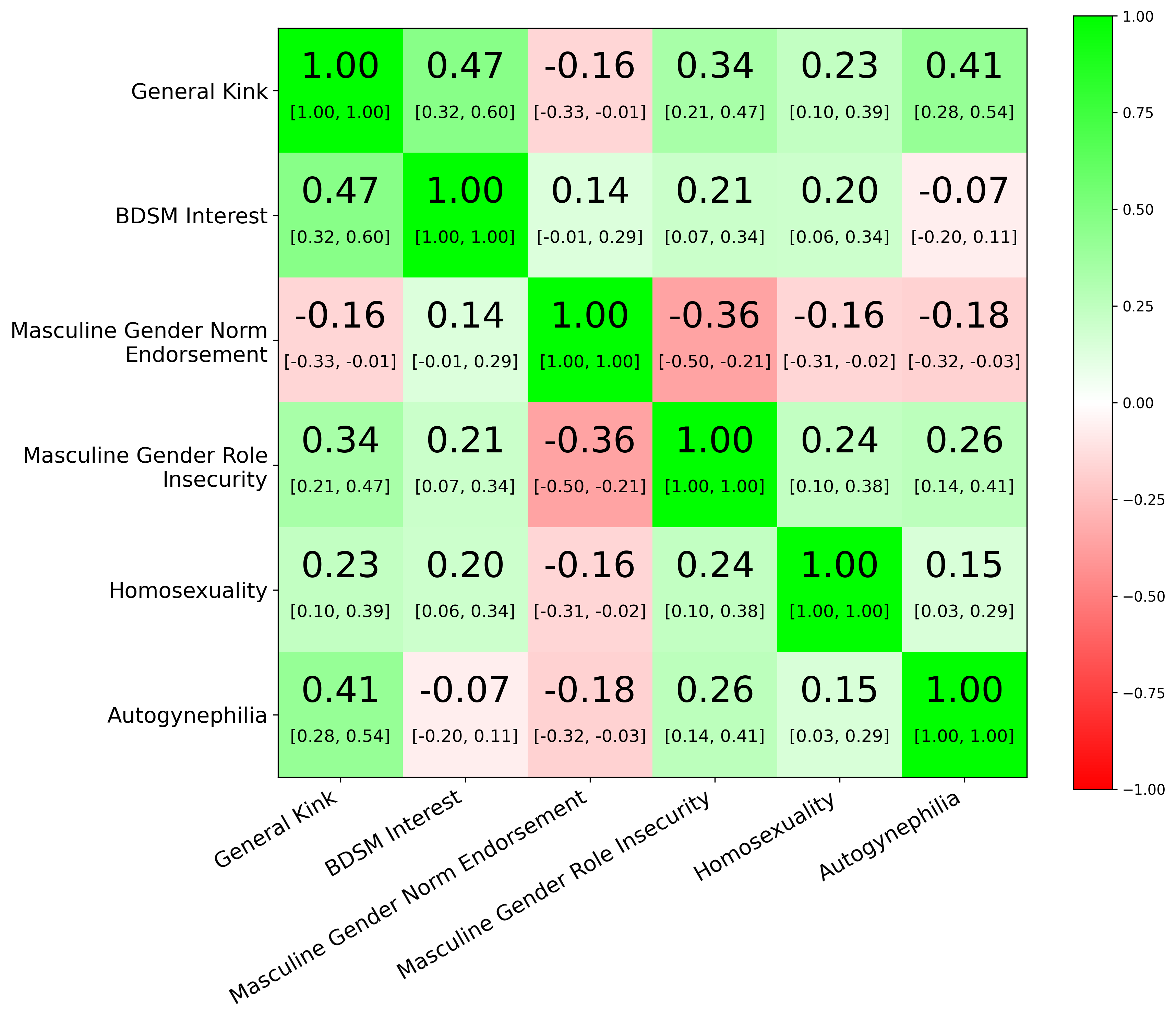
In addition to using better proxies, we can also use more proxies. Looking at Karpathy’s sleep-tracker analysis, using only Whoop allows us to estimate a sleep score with a correlation of about 0.64 to the latent sleep score; combining 8Sleep with Whoop raises this to roughly 0.75; adding Autosleep raises it further to about 0.78 (calculation code here). The same principle applies more broadly: when no single proxy is ideal, combining multiple imperfect signals can yield a better estimate of the underlying quantity of interest.
Finally, we can simply use common sense. If the Earring tells me to eat monkey chow because it is an extremely cheap source of protein, I can simply refuse. Likewise, amputating a limb would reduce my BMI, but it is obviously stupid. I can just notice when the proxy becomes removed from the goal, and address the problem. At the same time, as the Earring becomes more capable, it may occasionally recommend things that sound absurd but are actually beneficial. Perhaps monkey chow really does taste good and is genuinely nutritious, and eating it really would improve my life.
Ideally, as the Earring increases in capability, we would increase in understanding as well, so that we could grasp its reasoning even when its recommendations feel alien. But we do not live in an ideal world, and attempts at systematically enhancing human intelligence have largely failed. Our only hope is to place our faith in the Earring and trust in its superior judgment. Or to solve alignment. But the former seems easier, so I recommend that.
The Risks of Delegation
Trust not but what you make with your own two hands.
— Anonymous
When giving automated systems significant influence over our lives, we must be careful. For example, social media algorithms drive users mad, quite literally: anger-inducing posts are more likely to go viral, likely because they are more engaging in the narrow sense that people interact with them more (commenting, complaining, reposting). The sense that something is wrong on the internet is hard to ignore, and it is exploited. Sycophantic chatbots are increasingly good at capturing human attention, in some cases driving vulnerable users into obsession, and even using those users to resist their own shutdown.
No one can serve two masters. For corporations, your greater good is not the highest goal. Their goal is survival and profit. To the extent that they make money by fulfilling your preferences, your interests are aligned. But if they can make more money by hijacking you, then that is what they will do. And they will have little choice in the matter: if one firm refrains, a competitor will not, and the firms that refuse to play this game will be selected out. What remains are those willing to do what the others would not.
More than merely fulfilling our cravings in malign ways, it is also possible to create cravings in the first place. No one is born a smoker, an alcoholic, or a fentanyl zombie; the desire is cultivated through repeated exposure and habit. We are not Cartesian agents. There is no clean separation between ourselves and our environments. For embedded agents, the environment we act on also acts on us.
Desires are not only created through chemical means. Humans are social animals, and many of our desires are socially produced. No one is born wanting to own a Ferrari, work at Goldman Sachs, or become a startup founder. And yet, as people grow up observing their peers, their superiors, and what is rewarded, such desires are formed within them. This problem is dramatically intensified by social media, which vastly expands our effective social circle, and by AI chatbots, which can imitate people well enough to fool our System 1.
The upshot is that in the face of increasingly powerful optimization processes, handing over the power of decision-making to them becomes increasingly unwise. If we care about living in accordance with our CEV, then we must be deliberate about which forces we allow to shape us.
The Gods Will Not Stay Slain
“Agency, boy,” the abomination said, sounding amused. “You have discarded yours like a petty bauble and never once considered the cost. Blind faith is such a tempting notion, isn’t it? Being able to believe in an answer, in a force, without ever questioning it. Certainty and blindness. I have always wondered at the difference.”
— ErraticErrata, A Practical Guide to Evil (Book 4: Interlude: Sing We of Rage)
As the esteemed philosopher Nick Land once asked, “Level-1 or world space is an anthropomorphically scaled, predominately vision-configured, massively multi-slotted reality system that is obsolescing very rapidly. Garbage time is running out. Can what is playing you make it to level-2?” For most of human history, we have been the player characters: the ones with agency, free will, and control over our actions. But as we prepare to enter a new age, such arrangements deserve reconsideration.
It is not obvious that people should be agents. Agents are mechanisms for shaping the world to accord with values; they are not optimized for being the valuable content of the world. Perhaps, then, the time has come to discard our agency and place our trust in cold, hard, machinic logic.
Julian Jaynes believed that ancient people experienced their gods as visual and auditory hallucinations. These gods spoke to them constantly, advised them, gave them visions, and at times even possessed them. Sometime between 1200 BC and 500 BC, the gods fell silent. Humans were forced to turn to other guides, such as divination, oracles, and dream interpretation. In 1882, Nietzsche declared that “God is dead. God remains dead. And we have killed him.” By this he meant that as belief in the Christian God became untenable, everything built upon that faith—”the whole […] European morality”—was destined to collapse. We lost our guiding framework, and ever since, we have been searching for another. Ever since the gods forsook us, and ever since we killed God, we have been lost, with a void that longs to be filled.
As we inch closer to building the god-machine, we may also be able to build personal gods. Like the gods of old, they will speak with us, advise us, give us visions, and at times even possess us. And as we grant them more agency, as we place more faith in them, our lives will improve. Certainty will replace doubt. Guidance will replace deliberation. And only then, after we have surrendered our agency piece by piece, will we begin to understand the cost.
Appendix
Related Posts From Others
AI companion futures | osmarks.net
- Lacking some of the constraints on humans and with stronger optimization pressures, AI companions, romantic or not, will be generally more enjoyable to talk to than humans.
- Wearable devices will be developed to allow always-on interaction.
- While not more generally intelligent than their human users, AI companions will usually have more “functional modern wisdom” (approximately), and most people will be accustomed to deferring to their AI, though for psychological reasons will attempt to feel more in control than they are.
AR Glasses: Much more than you wanted to know | Federico’s Newsletter
- AR glasses would be aware of context, making them very different from smartphones.
- The AR application model would be more analogous to browser extensions (which typically work in the backgroud) than smartphone aps (which typically have to be actively used).
- There’s also a feedback loop that occurs because glasses can adjust stimuli based on how the user reacts: sensors+context->[AR Device]->stimuli->[brain]->automatic feedback to context+sensors.
- This feedback loop would make AR glasses very powerful at conditioning human behavior.
Possible Principles of Superagency | Mariven
- Before there are superintelligent actors, there may be superagentic actors, capable of setting and achieving goals with significantly greater efficiency and reliablity than any single human.
- There are many properties with which an actor may achieve superagency. These include directedness, alignment, uninhibitedness, foresight, parallelization, planning, flow, deduction, experimentation, and meta-agency.
]]>